Hoe gebruiken we data om inzicht te krijgen in de energieverbruiken van morgen?

Een accurate inschatting van de benodigde hoeveelheid elektriciteit is essentieel om vraag en aanbod op de energiemarkt met elkaar te matchen. De hoeveelheid in te kopen energie voor alle kleinverbruikers per kwartier is een vermenigvuldiging van drie componenten: het standaard jaarverbruik (SJV), de profielfractie (PF) en de meetcorrectiefactor (MCF).

Hierbij is het standaard jaarverbruik een schatting van het gemiddeld jaarlijks energieverbruik van alle aansluitingen die door VanHelder voorzien worden van elektriciteit. De schatting van het SJV is gebaseerd op de laatst bekende meterstanden en gegevens van de slimme meters. De profielfractie geeft voor ieder kwartier in een jaar aan welk gedeelte van het standaard jaarverbruik aan dat kwartier gealloceerd wordt, profielallocatie. Een jaar heeft (365x24x4=35.040) kwartieren, stel dat de verwachting is dat elektriciteitsverbruik volledig gelijkmatig over het jaar verdeeld is dan zou iedere profielfractie dezelfde waarde hebben, namelijk 1/35.040. In werkelijkheid fluctueren de profielfracties natuurlijk gedurende de dag en door het jaar heen. De profielfracties worden per jaar vastgesteld door NEDU, daarbij wordt rekening gehouden met factoren zoals, onder andere vakantiedagen en seizoenen. In werkelijkheid kan het verbruik hoger of lager uitvallen dan door deze profielallocatie bepaald wordt. De meetcorrectiefactor (MCF) corrigeert deze profielfracties naar boven of naar beneden. De MCF is een, op netniveau berekend, ratio van het daadwerkelijk verbruik tot het geschatte verbruik. Per definitie kan de MCF pas achteraf bepaald worden, als het daadwerkelijk verbruik over een periode bekend is. Een meetcorrectiefactor boven de een betekent dat de profielfracties het daadwerkelijk gebruik hebben onderschat en vice versa. Als het op een dag onverwachts heel zonnig is zal er veel stroom gegenereerd worden door zonnepanelen, de MCF zal daardoor waarschijnlijk naar beneden corrigeren met een waarde lager dan een.
Om van tevoren de juiste hoeveelheid energie in te kopen zal er dus een MCF voorspeld moeten worden. Het voorspellen van de MCF gebeurt door middel van een forecast. De keuze om de MCF te voorspellen in plaats van de uiteindelijke in te kopen hoeveelheid zorgt ervoor dat de voorspelling en inkoop van energie minder gevoelig is voor veranderingen in het onderliggend aantal aansluitingen. VanHelder gebruikt een enorme hoeveelheid data om zo’n voorspelling op te baseren. De variabelen die nuttig zijn gebleken zijn onder te verdelen in twee categorieën: tijdsaanduidingen zoals het uur van de dag of de dag van het jaar, en weersvariabelen zoals temperatuur en zonnestraling. Daarnaast is er de afgelopen jaren een dataset van historische MCF’s opgebouwd die gebruikt wordt om een model te leren patronen in de data te herkennen.
Er is een breed scala aan methodes om historische tijdsreeksdata om te zetten in een voorspelling, dit kan variëren van het simpelweg bepalen van een voortschrijdend gemiddelde tot het implementeren van een neural network. Deze laatste methode wordt ook door VanHelder gebruikt om de toekomstige MCF’s te bepalen. Een neural network is een deep learning model waarvan de structuur geïnspireerd is op het menselijk brein. Deep learning is een vorm van artificial intelligence waarbij machines getraind kunnen worden om op basis van grote hoeveelheden data complexe problemen op te lossen. Neural networks worden tegenwoordig op allerlei verschillende manieren ingezet, zo zijn ze bijvoorbeeld fundamenteel voor de aanbevelingsalgoritmes van streamingsdiensten en gezichtsherkenningsprogramma’s.
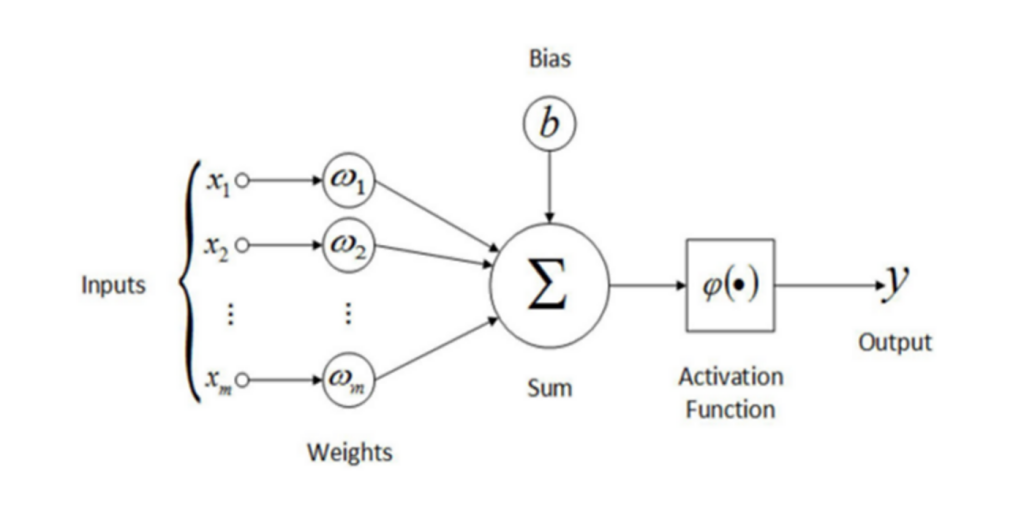
Een neural network bestaat uit drie layers:
de input layer, deze verwerkt alle variabelen die geselecteerd zijn om een voorspelling op te baseren (temperatuur, maand etc.)
de hidden layers, binnen deze layers vinden de berekeningen plaats en worden verbanden gelegd
de output layer, deze layer geeft de uiteindelijke voorspelling
Iedere layer bestaat weer uit nodes of neurons, in principe geldt: hoe meer layers en neurons hoe meer complexiteit het model kan blootleggen. Dit is niet altijd gewenst, soms is de relatie tussen twee variabelen lineair en onafhankelijk van andere variabelen, je wil dan voorkomen dat je een heel complex model gebruikt. De neurons in opeenvolgende layers zijn met elkaar verbonden via onderlinge connecties, zo kunnen ze informatie overbrengen. Deze connectie brengt de output van een neuron met een weegfactor w over aan de volgende neuron. Iedere neuron heeft ook een bias b en een activatie functie. De uiteindelijke waarde van een neuron j in layer h+1 wordt dus bepaald door een gewogen som van alle neurons in de voorgaande layer h te nemen, deze te corrigeren met de bias van de neuron j en vervolgens te transformeren met een activatie functie φ

Het aantal hidden layers en aantal neurons per layer kan vrij gekozen worden. De weegfactoren en biases zijn de parameters van het neural network. In de eerste iteratie van het trainingsproces begint het model met een willekeurig gekozen set parameters. Het zal dan een voorspelling maken en deze vergelijken met de gewenste uitkomst. Het model zal vervolgens iedere iteratie gebruiken om de parameters dusdanig te optimaliseren zodat de output van het model zo dicht mogelijk bij de gewenste uitkomst liggen. Het verschil tussen de voorspelde uitkomst en de historische MCF kan worden weergegeven door verschillende statistieken, veel gebruikt is de gemiddelde kwadratische afwijking. Zo’n gemiddelde kwadratische afwijking (mean squared error (MSE)) kan worden weergegeven als een formule met de parameters van het neural network als variabelen.

Waarbij m het aantal trainingsobservaties is, iedere x is de output van node i in layer h en wordt dus zelf ook weer gedefinieerd door de gewogen som van de outputs van de nodes in een voorgaande layer. De parameters van een layer zijn voor gemak van notatie samengevoegd in θ. Het model berekent dan een meerdimensionale afgeleide van deze gemiddelde kwadratische afwijking, een gradient. Op basis van deze gradient en learning rate α worden de parameters aangepast in de volgende iteraties, dit proces herhaalt zich totdat er geen verbetering in de resultaten meer optreedt.

Een deel van de data wordt gebruikt om te kijken of het getrainde model ook gegeneraliseerd kan worden naar data die het nog niet gezien heeft. Als het model eenmaal getraind en gevalideerd is is kan het worden ingezet om een voorspelling voor de toekomst te maken.
Meer weten?
We geven graag antwoord op al je vragen. Je kunt ons 24/7 telefonisch bereiken op 020 205 0485. Per e-mail kan ook, stuur je vraag dan naar vraag@vanhelder.nl.